
浙江寧波供電公司電力數據助城市治理提效
大數據2025-07-29
近日,濤思數據線上正式發布 TDengine IDMP,一款 AI 原生的物聯網、工業數據管理平臺。這是我在時序數據庫上專注耕耘八年之后,推出的第二款產品。今天一早起來,看到各種留言,以及后臺看到的下載量與注冊用戶數,我異常興奮,覺得自己作為一個程序員,在 AI 時代不僅不會被替代,而是找到了可以再戰八年的巨大機會。開發這款產品是繼我 2019 年將 TDengine 核心代碼開源后的又一重大決定。今天靜下心來,花 2 個小時把我的心路歷程寫下來,分享給眾多的創業者,特別是想在 AI 浪潮里沖浪一把的程序員們。
2016 年底,我看到萬物互聯的時代已經到來,各行業需要一個高效的處理海量時序數據的引擎,因此創立濤思數據,并且自己沖到開發第一線,2 個月就寫下了 1.8 萬行 C 代碼,而且大膽的在 2019 年 7 月將 TDengine 核心代碼開源。八年過去,TDengine 的全球安裝量已經超 83 萬套,日安裝量超 700 套,付費客戶超 500 家,遍布全球 60 多個國家和地區,集中在電力、新能源、石油、智能制造、汽車、交通等多個行業,這些數字讓我相當開心。
海量數據有了,然后呢?
但過去幾年,我走訪了中國以及歐美的很多客戶,了解到大家的數據量是真的大,比如某個新能源集控中心,測點數超過 5000 萬,每天產生的數據量超過 5 TB。TDengine 時序數據庫的高效寫入、高壓縮率的存儲與低延時的查詢很讓客戶滿意,但大家都有一個共同的問題:數據已經采集和存儲,下一步,怎么把數據的價值挖掘出來?我也一直在思考這個問題,希望可以用技術的方式來幫助大家。作為一個程序員,很直接的想法就是讓 TDengine 提供更好的 SQL 查詢,提供更好的流式計算能力。因此,今年 3 月,我們又推出 TDgpt 時序數據分析 AI 智能體,利用 AI 來提供時序數據預測、異常檢測與數據補全、分類的服務。但即便有了這些,用戶依舊還是在問如何挖掘數據的價值。
認真分析后,我們發現:最大的問題是業務人員與 IT 工程師、數據分析師之間存在“代溝”。一方面,業務人員需要的是能馬上獲得業務的實時洞察,但系統往往只提供固定的報表、看板,每次業務人員有什么想法,一定要找 IT 工程師或數據分析師先溝通,解釋業務的邏輯和需求。另外,因為大多數 IT 工程師不懂業務本身,雖然知道怎么用數據庫,知道怎么寫 SQL,但要先理解業務、理解需求,才能寫出來代碼,因此往往幾天之后才會有分析結果。一旦分析的結果不實時,大家對數據價值挖掘的興趣就大幅下降。市面上已經有不少 BI 工具,通過拖拉拽可以緩解問題,但業務人員會直接操作 BI 工具的,比例很小,大多數還是嚴重依賴數據分析師或 IT 工程師。此外還有,業務人員的行業知識和經驗積累還不夠,特別是對新的領域,比如新能源,沒有形成系統全面的知識和思考,因此他們也很難提出清晰具體的實時數據分析需求。
TDengine 核心代碼在 GitHub 開源
“身上沒有煙味 ……”,無解的局面
作為一個時序數據庫廠商,我覺得自己進入了一個無解的局面,因為我比用戶的 IT 工程師更不懂業務。當我與卷煙廠的工程師交流時,他們說“你身上都沒有煙味”;當我去油田交流時,我都不知道油井采集了哪些物理量;當我去污水處理廠交流時,他們提到的一些專有名詞我都完全沒聽說過。此外,我還發現,基于數據庫做應用的廠商多如牛毛,每個行業都有一批應用公司,但沒有一家能做到行業通吃,因為他們遇到了和我們同樣的問題,對行業不了解,不具備行業知識,那自然不會被客戶所接受。
我一直在把 TDengine 時序數據庫作為人生最后一個產品在做,在這個細分賽道堅持了 8 年,希望這個產品給自己超過 40 年的程序員生涯畫上一個完美的句號。但基于其產品的特性,行業知識的壁壘,除非做行業以及客戶的定制化開發,否則我很難將 TDengine 產品做厚,進軍到應用領域。我經常給團隊鼓氣,希望濤思數據能做到 100 億 RMB 的市值,但其實背后,是我理性的思考,拼命努力做到極致的話,公司市值也就一百億,至多兩百億 RMB。
但這一切,由于 AI 大語言模型,發生了改變,而且讓我這個 57 歲程序員倒騰的歷史又濃墨重彩的加上了一筆。
一開始,我也想開發Chat BI
2024 年 8 月,我在美國硅谷與做 Chat BI (對話式商業智能) 的公司交流,發現我們完全可以做,至少可以提供自然語言的接口讓用戶不用寫 SQL 來查詢數據。但仔細思考,發現 Text to SQL 不是一件容易的事。人類語言靈活、模糊、上下文依賴,而數據庫 SQL 語言嚴謹、精確、結構化,兩者之間存在巨大鴻溝。怎么將自然語言中的詞語映射到數據庫表名、列名,怎么確認多個表之間的關系,怎么將不同行業的業務語義匹配到計算函數,而且 SQL 的復雜性,比如嵌套查詢、聚合函數、條件表達式等,讓 Text to SQL 生成的準確性大打折扣。此時,我心里想的還是怎么找到頂尖的 AI 人才來解決這些問題。
所幸,我一直關注研究 Aveva 的產品 PI System,它是一款工業數據管理的軟件,內核也是時序數據庫,但帶有數據采集、可視化、分析、事件管理等功能。不像 TDengine TSDB 更多被集成商所使用,PI 可以交付給最終用戶直接使用,在發電、電網、石油、化工、制造等行業有相當大的用戶群。帶著 Text to SQL 的問題,我再看 PI System 的時候,豁然開朗。
我們必須建立數據目錄,對于物聯網、工業場景而言,最有效的數據目錄就是樹狀層次結構,不僅讓大家找數據資產時方便,而且符合企業管理的習慣;我們必須做數據的標準化,因為系統會對接眾多的數據源,每個數據源的采集量的名稱、計量單位都不一致,不先標準化,只會讓 Text to SQL難上加難;我們必須做數據的情景化,數據沒有足夠的描述信息,業務上下文和語義,AI 無從幫你。因此我決定參考 PI,把數據目錄、數據標準化、數據情景化做好,并提供工具讓數據建模的過程變得簡單高效,把 TDengine 改造為一個 AI-Ready 的數據平臺。十月國慶節一結束,新的 IDMP ( Industrial Data Management Platform,工業數據管理平臺) 研發小組正式組建,亞強帶著丁博、秦沖好幾個同學開干了。
IDMP 研發小組決定用 Java 開發,采用 Quarkus 框架。我是 C 程序員,因此逼迫自己也安裝了整個 Java 開發環境,開始寫 Java 程序。作為一家以技術、以產品立身的公司,我深知,產品必須親自抓。但那個時候,我還是沒有最大程度的投入,因為我覺得 Chat BI 提效了不少,但離問題的完美解決還有差距,因此只是邊做邊思考,想到更多的是利用 IDMP 的開發倒逼 TDengine TSDB 的開發,比如虛擬表,流式計算重構等,目的是讓 TDengine 時序數據庫更扎實,功能更強大,更有市場競爭力。
前所未有的機會
春節期間,DeepSeek 極其火爆,讓我認真思考,作為一家時序數據庫公司,我們在 AI 的浪潮里,到底能做什么?一天與搭檔 Steven 討論產品 IDMP 是否內嵌 Grafana 做可視化時,我們腦洞大開。我們不應該只支持自然語言去創建面板,而是應該借助 AI 大語言模型的能力將可視化面板主動推送給用戶,像抖音一樣。對于我們處理的物聯網、工業場景,每個行業都有自己關心的指標、面板、報表與實時分析,AI 完全可以基于采集數據的上下文,智能感知出來是什么業務場景。感知場景后,AI 這個超級大腦自然知道應該創建哪些典型面板與報表了。我立即用 DeepSeek 做了一些測試,發現完全可行。我在把自己熟悉的 IT 運維場景,采集的物理量等寫好一個提示詞發給 DeepSeek 后,它給了我遠超我自己經驗的答案。
這一下讓我興奮到了極點,真正的機會來了。
因為如果我們能自動推薦可視化面板、自動創建實時分析任務給用戶,那就意味著用戶過去要花相當長的時間學習 SQL,學習做報表、面板,更要花時間學習行業知識,積累行業的運營經驗,現在一概不需要或幾乎不需要了。業務洞察不再強依賴于 IT 工程師,不再強依賴于數據分析師,甚至不再強依賴于業務專家,人人都可以隨時獲得。AI 已經能生成精彩的文章、圖片、視頻,甚至 PPT,如果能生成生產運營過程中所需要的可視化面板、報表,創建實時分析報警任務,那就等于將 AI 技術真正落地到了國計民生的主戰場:工業場景。無論電力、新能源、石油、石化、智能制造、礦山,還是污水處理,都將迎來跨越式的數智化轉型。特別是對于中國乃至全球的數百萬家中小企業而言,相當于瞬間擁有了以前大公司才會有的數據分析工具和人才,能基于生產和運營數據實時做出最佳的商業洞察和決策。
這個市場遠超我們已在的時序數據庫市場,如果成功,至少可以做到 1000 億 RMB 的規模。從我三次創業的經驗來看,這個蛋糕實在是太大,太誘惑,對我們團隊而言也可謂是萬事俱備。資金、團隊都不是問題,所要的只是我作為創始人與 CEO 的決心。
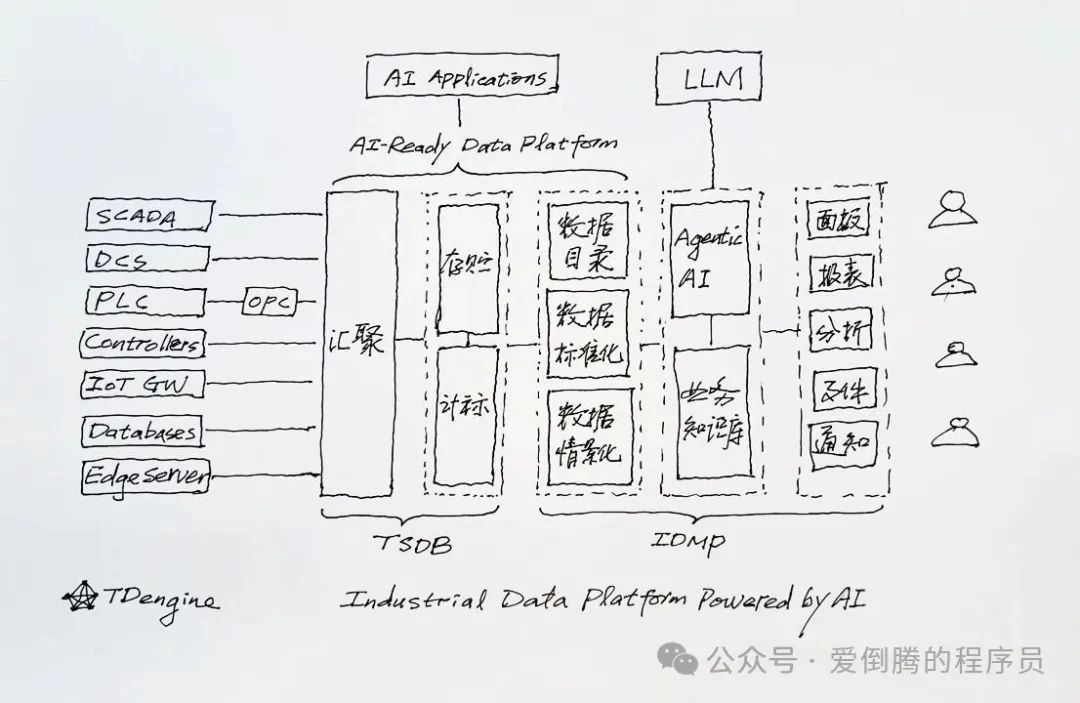
AI 驅動的工業數據管理平臺整體架構圖
一路狂奔
因此,我立即回到北京,將公司幾乎所有的研發資源傾斜過來,全力投入到 IDMP 的研發中,而且在公司所有的會上強調“all in AI”。我自己身先士卒,每周七天,平均每天工作 14 個小時,除了無法推脫的客戶交流,將自己的時間全部安排給了新的產品研發,全部投入到了產品定義、產品設計以及 AI Agent 模塊上。
很快,我們就定出來 AI 驅動的物聯網、工業數據平臺的設計,大家就熱火朝天的干起來。
我是一個注重細節的人,每個小小圖標,每個頁面的跳轉,每段小小的提示語,無論中文還是英文,字體字號行距,都會細細琢磨,而且還要做開發進度、技術實現難度與細致度的平衡。雖然有 AI 幫助,但它無法代替原創性的思考和設計。相對于那些老掉牙還在 Windows 上跑的 PI System 以及眾多的工業實時數據庫軟件,以及大堆粗制濫造的工業互聯網平臺軟件,我們不僅用 AI 技術解決了業務洞察難以實時獲取的難題,用戶體驗也得到飛躍提升——用戶不必再翻查厚重的手冊,這令我無比自豪。
我自己帶著團隊一路狂奔,唯恐被 Siemens, Schneider, GE, Aveva 這些工業軟件巨頭搶了先機。在亞強、勝亮、潘魏、王旭、丁博、元湃、營昭等幾十位研發同學沒日沒夜的努力下,終于在 7 月 29 號發布了 TDengine IDMP 第一個正式版本 1.0,大家都可以用容器或虛機免費下載體驗,而且為降低體驗的門檻,我們同步推出相應的免費云服務。讓我特別驕傲的是,濤思數據是全球第一家推出“無需提問,直接用 AI 自動生成可視化面板、生成實時分析任務”的公司。
奔跑了半年,終于可以緩一口氣。
當然,這只是 IDMP 的第一個版本,產品后續還會快速迭代。在今年接下來要發布的版本中,將會包含我自主設計的、極具創新性的數據模型版本控制功能,同時還會新增一些行業必需的地圖、組態等面板功能,以及事件根因分析報告自動生成、事件分析面板、數據質量報告等功能,并且會支持第三方時序數據庫。
無問智推,數據消費范式的改變
TDengine 的創新突破與工程技術落地,正在推動數據消費范式的根本性轉變(Data Consumption Paradigm Shift)。傳統的數據分析模式中,始終是用戶主動發起請求(比如通過 SQL 查詢),再由系統響應并返回結果。而現在,借助 LLM 與 AI Agent 技術,數據能夠實現 “主動開口”—— 業務分析的核心洞察會直接推送給用戶,讓分析模式從 “拉取(Pull)” 徹底轉向 “推送(Push)”。這意味著用戶的數椐消費變成了被動接收,數據分析由此邁入 “抖音時代”,門檻被直接降至零。如果說 Chat BI 的 “智能問數” 是 “有問才答”,那么 TDengine 這種從拉到推的模式,不妨稱之為 “無問智推”。
通過一系列包括數據目錄,數據標準化和數據情景化的基礎性工作,以存儲和計算為核心的數據庫被改造成為 AI-Ready 的數據平臺。借助 LLM,這個 AI-Ready 的數據平臺成為了一個自治的數據平臺(Autonomous Data Platform),一個自我驅動(Self Driving)的實時分析平臺,數據自己就能說話,業務洞察不再依賴用戶的行業知識積累和工具使用技能。而因為有了掌握人類所有知識的 LLM 加持,一個 2B 工具,就不會再局限于一個或幾個行業,而是能運用到幾乎所有行業。這樣,在 AI 的驅動下,一個優秀的 2B 軟件或云服務將擁有更為廣闊的市場,將把傳統碎片化的市場匯聚起來。
TDengine 將更進一步,將 AI-Ready 的數據通過開放的 API 給第三方應用提供。它提供的不再是傳統的數據庫的 SQL 查詢結果,而是帶有數據業務語義、帶有數據上下文的 AI-Ready 的查詢結果,賦能給眾多的 AI 應用,讓數據的擁有者能最大程度的挖掘出數據的價值。
TDengine 的創新與工程實踐只是開了行業的先河,我相信今后會有很多類似“無問智推”系統的出現,并流行起來,數據庫以及數據基礎設施在 AI 時代將被重構,以適應 AI 應用發展的要求。希望 TDengine 能成為變革后的王者。
有了目標,就能一直跑
在創辦濤思數據 TDengine 的前三年,我將自己視為產品研發的核心,寫了太多行程序,解決了太多的 BUG,讓自己在 50 歲的時候居然進入了研發的巔峰期。但過去的幾年,節奏開始慢了下來。半年前,當我意識到 AI 技術能給數據庫、數據基礎設施行業帶來新的重大變革,能解決物聯網、工業數據處理領域的難題的時候,我一下又回到了巔峰狀態,直接沖到產品研發的第一線,每天都有用不完的力氣。
2016 年以前我從不跑步,但偶然的原因,跑起步來。而且這一跑就不可收拾,還越跑越快,越跑越遠。第一次跑北京奧森,十公里氣喘吁吁的花了 65 分鐘,現在跑個半馬,只要一小時 55 分。過去的 9 年,我累計跑了至少 2 萬公里,北京到紐約一個來回的距離,我根本沒想到自己還有這樣的潛能。
從我個人的經驗來看,做產品研發與跑步一樣,巔峰不由年齡,而是由夢想和決心來決定。沒有目標,每一步都是負擔,多跑一步都會覺得累;有了目標,每一步都是希望,多跑一步,就多一份喜悅。一旦下決心開發出一款受人喜愛的產品,年齡不再是問題,你一定會有足夠的精力去投入。

參加北京國際長跑節半程馬拉松
我堅信,通過 AI 技術的加持,并充分利用中國巨大的工業制造市場,再輔以開源、云服務等手段,我們能將傳統的工業數據管理平臺徹底顛覆。相對于 PI System 以及傳統實時數據庫而言,TDengine 展現的是代際優勢,一定能將他們逐步淘汰。工業軟件的世界舞臺,不再只屬于 Siemens, Schneider, GE 等公司,也會有 TDengine 的身影,我們不只是追趕者,而是領航人。
我一直覺得自己很幸運,湖南農村長大,但在中國和美國都受到了很好的教育,并且趕上了互聯網、移動互聯網的浪潮,在本該游山玩水的年齡,又倒騰上了時序數據庫,居然能有超 80 萬套的安裝量。如今AI浪潮席卷而來,慶幸自己還在牌桌上,而且手里抓的牌還不錯,必須打出精彩。
雖然已經 57 歲,寫程序超過 40 年,但繼續奔跑,再來八年又何妨?Leave a dent in the world!
陶建輝,北京濤思數據科技有限公司(TAOS Data)創始人,公司專注時序空間大數據的存儲、查詢、分析和計算,不依賴任何開源或第三方軟件,開發了擁有自主知識產權、100% 自主可控的 AI 驅動的物聯網工業大數據平臺 TDengine。



網站簡介| 服務項目| 廣告服務| 用戶注冊| 幫助信息| 聯系我們| 友情連接
網站運營:北京中電創智科技有限公司
服務熱線:400-007-1585 在線投稿
網站錯誤舉報電話:18610433258
《 中華人民共和國電信與信息服務業務經營許可證 》編號:京ICP證140522號 京ICP備14013100號-2 京公安備11010602010147號






評論